스프링과 객체지향 설계
6. 안티패턴
6.1 스마트 UI
스마트 UI 패턴은 에릭 에반스(Eric Evans)의 도메인 주도 설계에서 소개되어 유명해진 패턴이다.
스마트 UI란 시스템의 UI레벨에서 너무 많은 업무를 담당하는 것을 말한다.
- 스마트 UI는 데이터 입출력을 UI 레벨에서 처리
- 스마트 UI는 비즈니스 로직도 UI 레벨에서 처리
- 스마트 UI는 데이터베이스와 통신하는 코드도 UI레벨에서 처리
백엔드 개발자에게 UI, 즉 의사소통하기 위해 사용되는 인터페이스가 바로 API이다. 그리고 컨트롤러(Controller)는 API를 만드는 컴포넌트이다. 그렇기에 컨트롤러는 스프링에서 UI를 만드는 도구라고 볼 수 있다. 스프링에서 스마트 UI는 컨트롤러의 핸들러 메서드에 지나치게 많은 로직이 들어가 있는 경우를 의미한다.
컨트롤러의 역할은 엔드포인트를 정의하고 API 사용자의 요청을 받아 그 결과를 응답 포맷에 맞춰 반환하는 것이다.
- APi 호출 방식을 정의
- 어떤 비즈니스 로직을 실행할 것인지 결정
- API 호출 결과를 어떤 포맷으로 응답할지 정의
스마트 UI는 비즈니스 로직이 UI 수준인 컴포넌트에 위치해 있다. 일반적으로 UI는 사용자의 입출력을 위한 창구로만 사용돼야 한다. 입력을 받고 이를 뒷단으로 넘겨 비즈니스 로직을 실행하는 역할 정도여야 한다. 하지만 스마트 UI 패턴을 따르는 코드에선 그렇지 않고 UI 코드에 과한 책임이 할당돼 있다.
스마트 UI에서 말하는 '스마트'는 UI 코드가 정말 똑똑하게 동작해서 그렇게 부르는 것이 아니라 지나치게 많은 일을 처리하고 있는 상황을 비꼬는 것이다. 이러한 방식으로 개발된 애플리케이션은 설계에 구조라고 부를 만한 것이 존재하지 않는다. 모든 코드가 오롯이 기능이 동작하게 만드는 데만 초점을 맞춰 작성된다. 때문에 사실상 모든 API는 어떤 스크립트를 실행하고 응답하는 수준에 그친다. 이러한 코드는 당연히 확장성이 떨어지고 유지보수성도 떨어진다. 이러한 이유로 스마트 UI는 안티패턴이다.
6.2 양방향 레이어드 아키첵처
두번째로 소개할 안티패턴은 '양방향 레이어드 아키텍처(bidirectional layered architecture)'다. 이는 레이어드 아키텍처(layered architecture)를 지향하는 프로젝트에서 많이 발생하는 안티패턴이며, 레이어드 아키텍처에서 정의한 레이어들의 의존 관게에 양방향 의존이 발생하는 경우를 칭한다.
레이어드 아키텍처는 소프트웨어 시스템을 설계하는 방식 중 하나로, '레이어'라고 불리는 분류 체계를 사용한다. 개발하기 전에 레이어를 먼저 정의하는데, 보편적으로 아래와 같은 3개의 레이어를 사용한다.
- 프레젠테이션 레이어(presentation layer): 이 레이어에서는 사용자와의 상호작용을 처리하고 결과를 표시하는 역할을 담당한다. 그리고 이 역할을 처리하는 대표적인 스프링 컴포넌트가 바로 컨트롤러 컴포넌트이다.
- 비즈니스 레이어(business layer): 이 레이어에서는 애플리케이션의 비즈니스 로직을 처리하는 역할을 한다. 그래서 데이터의 유효성 검사, 데이터 가공, 비즈니스 규칙 적용 등의 일이 이 레이어에서 이뤄진다. 이러한 성격 때문에 스프링에서 주로 서비스 컴포넌트가 이곳으로 모인다.
- 인프라스트럭처 레이어(infrastructure layer): 이 레이어에서는 외부 시스템과의 상호작용을 담당한다. 예를 들어, 대표적인 외부 시스템으로 데이터베이스가 있다. 그래서 스프링에서 데이터에 접근하는 기술은 JDBC(Java Database Connectivity)나 ORM 프레임워크인 JPA, 하이버네이트 관련 코드들이 이 레이어에 배치된다. 따라서 이 레이어에 주로 들어가는 코드는 데이터를 저장하거나 조회하는 등의 일을 수행하는데, 그러한 이유로 이 레이어는 좁은 의미에서 '영속성 레이어(persistence layer)'라고 불리기도 한다.
레이어드 아키텍처를 따라 만든 패키지를 살펴보자. 이렇게 구성했을 때 얻을 수 있는 장점은 무엇일까?

가장 큰 장점은 '단순하고 직관적은 구조'라는 것이다. 즉 어떤 컴포넌트를 개발하거나 찾아야 할 때 컴포넌트를 어디에 위치시켜야 할지 고민할 필요가 없다. 컴포넌트의 유형이 무엇인지만 떠올리면 어떤 레이어에 위치해야 하거나 접근해야 하는지 바로 알 수 있다.
각 컴포넌트 위치들이 너무 명확하기에 새로운 요구 사항이 생겼을 때, 개발자는 구조적으로 깊게 고민할 필요가 없이 '엔드포인트는 어떻게 생겼는지', '비즈니스 로직은 어떻게 만들면 될지' 정도만 고민을 하며 개발을 할 수 있다. 그러니 (단기적으로 개발이 쉬워지는 것이다.
양방향 레이어드 아키텍처는 레이어드 아키텍처를 지향해 개발했지만, 레이어드 아키텍처가 반드시 지켜야할 가장 기초적인 제약을 위반할 때를 지칭하는 말이다. 그리고 여기서 가장 기초적인 제약이란 '레이어 간 의존 방향은 단방향을 유지해야 한다.'라는 것이다.
간혹 레이어드 아키텍처를 사용하는 조직에서는 편의상 하위 레이어에 있는 컴포넌트가 상위 레이어의 존재하는 모델을 이용하는 경우가 발생한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | @Service @RequiredArgsContructor public class PostService { private final PostJpaRepository postJpaRepository; @Transactional public Post create( long cafeId, PostCreateRequest postCreateRequest) { // API 요청을 받는 모델인데 비즈니스 레이어에서 사용함 // 생략 } } | cs |
PostCreateRequest 클래스는 API 레이어의 모델이다. API로 들어오는 요청을 @RequestBody를 이용해 매핑하려고 만든 객체인데, 하위 레이어에서 존재하는 서비스 컴포넌트로 전달해 서비스에서 이를 사용하고 있는 상황이다.
비즈니스 레이어에 위치한 서비스 컴포넌트가 프레젠테이션 레이어에 위치한 객체에 의존하는 바람에 두 레이어 간에 양방향 의존 관계가 생겼습니다. 이처럼 레이어 간에 양방향 의존성이 생긴 상황을 가리켜 '양방향 레이어드 아키텍처'라고 부른다.
그리고 이것이 바로 또 하나의 안티패턴이다. 이렇게 양방향이 생기면 애써 정한 레이어의 역할이 의미가 없어져 버리며 계층이 무너져버린다. 레이어 간에 양방향 의존성이 생겼다는 것은 순환 참조가 발생했다는 말이며 분리된 레이어가 하나로 통합됐다는 것과 같다.
그렇다면 레이어 간에 양방향 참조가 생겼을 때 이를 해결하는 방법은 무엇일까? 두가지 방법을 살펴보자.
6.2.1 레이어별 모델 구성
첫 번째 해결 방법은 레이어별로 모델을 따로 만드는 것이다. 위 코드 상황을 예시로 들면 비즈니스 레이어에서 사용할 PostCreateCommand 모델을 추가로 만드는 것이다. 이 모델은 프레젠테이션 레이어에 존재하는 PostCreateRequest 모델에 대응하는 모델이다.
PostCreatreCommand 클래스는 비즈니스 레이어에 위치한다. 여기서는 다음과 같은 명명 규칙을 사용한다.
- ~Request 클래스는 API 요청을 처리하는 모델이다.
- ~Command 클래스는 서비스에서 어떤 생성, 수정, 삭제 요청을 보낼 때 사용하는 DTO다.
이렇게 Request와 Command 클래스를 구분하고 컨트롤러는 서비스에 요청을 보낼 때는 PostCreateRequest 클래스를 PostCreateCommand 클래스로 변경해 서비스의 메서드를 호출한다. 이제 아래와 같은 구조로 변경된다.

의존 방향이 단방향이 되고 순환 참조가 사라졌다.
이 방법을 사용했을 때에 취할 수 있는 또다른 장점은 바로 클라이언트가 API 요청을 보내는 시점의 요청 본문(request body)과 서비스 컴포넌트에서 사용하는 DTO를 분리할 수 있다는 점이다.
PostCreateRequest에 writerId라는 값도 포함되어 있다고 할 때 이 값은 사용자가 임의적으로 조작해서 API 요청을 보낼 수 있다. 이러한 상황을 막기 위한 방어 로직이 시스템이 있냐 없냐의 문제가 아니라 처음부터 이렇게 신뢰할 수 없는 값은 아에 존재하지 않는 것이 좋다. 하지만 동시에 꼭 필요한 값이다. 이럴 때 '레이어별 모델 구성하기'가 빛을 바라는데, PostCreateRequest 클래스에는 writerId 필드를 넣지 않고, PostCreateCommand 클래스에는 이 값을 갖고 있게 한다. 그리고 PostCreateCommand 클래스에서 사용할 writerId 값은 userPrincipal 같은 값에서 가져오면 된다!
물론 단점도 있다. 대표적인 단점 중 하나는 작성해야 하는 코드의 양이 늘어난다는 것이다. 작성해야 하는 코드가 늘어난다는 것은 조직 관점에서 비용이 증가한다는 의미다. 그러니 모델은 적당히 세분화되고 적당히 통합돼야 한다. 그래서 그 사이에서 균형을 잡는 것이 매우 어려운 일이다.
6.2.2 공통 모듈 구성
두 번째로 소개할 방법은 순환 참조를 해결하는 방법과 비슷한 방법으로 공통으로 참조하는 코드를 별도의 모듈로 분리하는 것이다. 다시 말해 모든 레이어가 단방향으로 참조하는 공통 모듈을 만들고, PostCreateRequest 클래스 같은 모델을 그곳에 배치하는 것이다.
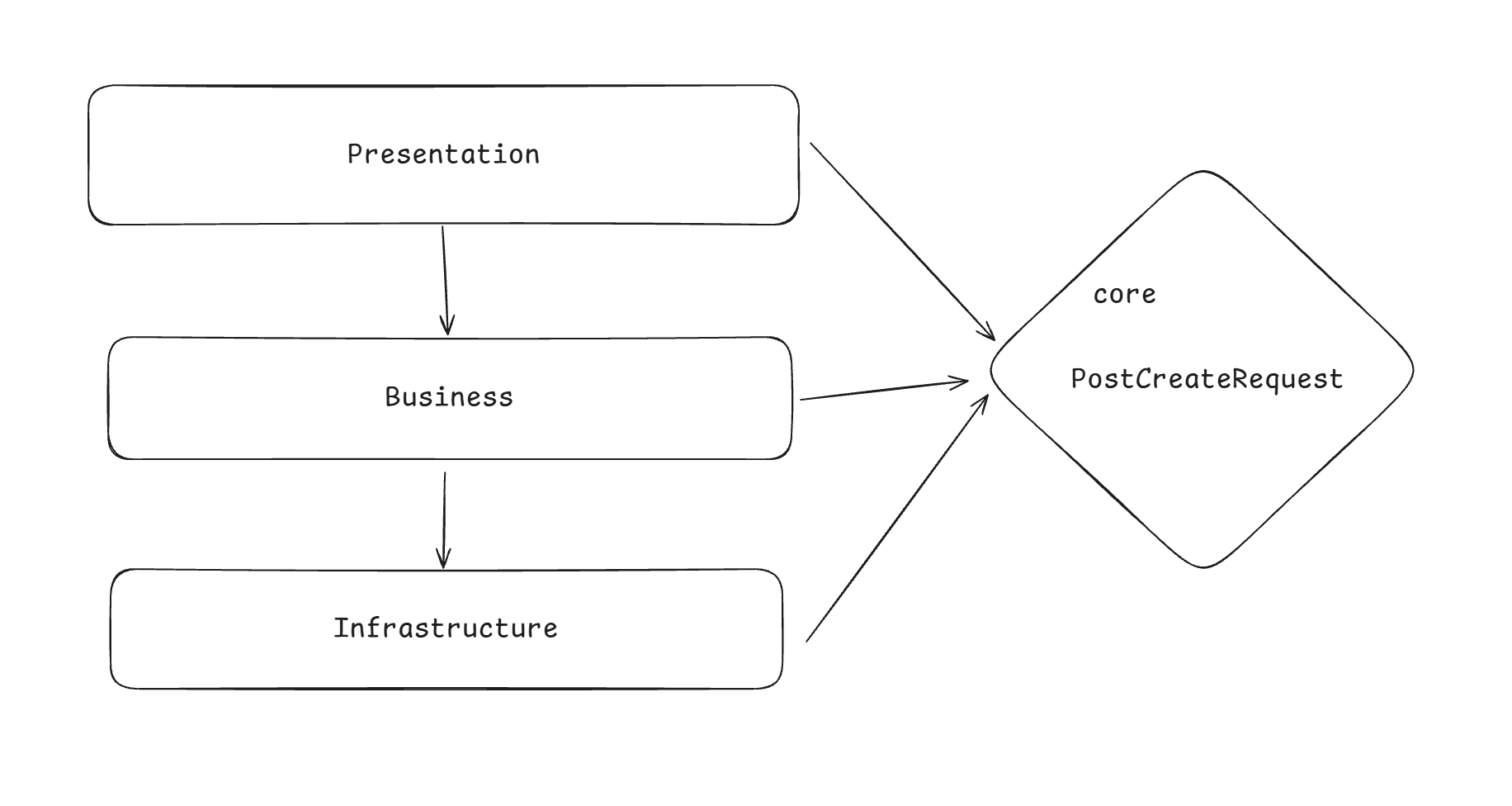
두 레이어가 바라보는 모델을 공통 모듈로 분리함으로써 이 문제를 해결했다. 간단하지만 가장 확실한 방식이다 .공통 모듈로 분리한다는 전략은 범용적으로 사용할 수 있는 유틸성 클래스들을 한곳에 모아둘 때 유용하다.
위 그림을 보고 몇가지 의문이 생긴다.
- core 모듈은 레이어인가?
- core 모듈이 레이어라면 모든 레이어가 바라보는 하나의 레이어가 있어도 괜찮을까?
질문을 하다보니 질문이 더생긴다.
- 레이어드 아키텍처에서 말하는 레이어가 뭘까?
- 레이어와 모듈의 차이는 뭔가?
레이어와 모듈 차이는 나중에 알아보기로 하고, core 모듈이 레이어인지에 대한 질문에 먼저 답해보면, 공통으로 참조할 수 있는 모듈을 만들어 보란 의미지 공통된 레이어를 만들라는 의미가 아니었다. 때문에 core는 모듈이며 레이어가 아니다.
6.3 완화된 레이어드 아키텍처
컨트롤러가 리포지터리를 사용하는 것은 괜찮을까? 생각만해도 눈살이 찌푸려진다. 이렇게 상위 레이어에 모든 하위 레이어에 접근할 수 있는 권한을 주는 구조가 '완화된 레이어드 아키텍처'라고 부른다.
완화된 레이어드 아키텍처는 스마트 UI 같은 코드가 만들어진다. 이런 구조에서는 기능 개발을 위한 코드가 어디에 어떻게 들어가야 할지 한눈에 파악하기 힘들다. 예를 들어 비즈니스 로직은 어디에 들어가야 할까? 레이어드 아키텍처를 설명하면서 원칙적으로 비즈니스 로직은 비즈니스 레이어에 들어가야 하지만 이러한 규칙은 완화된 레이어드 아키텍처에서는 의미가 없다.
따라서 비즈니스 로직은 개발자의 기분에 따라 그날그날 매번 다른 곳에 작성된다. 컨트롤러에도 작성되고 서비스에도 작성되고 도메인에도 작성된다. 그래서 레이어드 아키텍처에는 '레이어 간 통신은 인접한 레이어끼리 이뤄져야 한다.' 같은 제약이 있는 것이다.
6.4 트랜잭션 스크립트
트랜잭션 스크립트는 비즈니스 레이어에 위치하는 서비스 컴포넌트에 발생하는 안티패턴이다. 트랜잭션 스크립트는 서비스 컴포넌트의 구현이 사실상 어떤 '트랜잭션이 걸려있는 스크립트'를 실행하는 것처럼 보일 때를 말한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | @Service @RequiredArgsContructor public class PostService { private final PostJpaRepository postJpaRepository; private final BoardJpaRepository boardJpaRepository; private final CafeMemberJpaRepository cafeMemberJpaRepository; @Transactional public Post create( long cafeId, long boardId, PostCreateCommand postCreateCommand) { long currentTimestamp = Instant.now().toEpochMillis(); CafeMember cafeMember = cafeMemberJpaRepository .findByCafeIdAndUserId(cafeId, postCreateCommand.getWriterId()) .orElseThrow(() -> new ForbiddenAccessException()); User writer = userJpaRepository .findById(postCreateCommand.getWriterId()) .orElseThrow(() -> new UserNotFoundException()); Cafe cafe = cafeMember.getCafe(); Board board = boardJpaRepository .findById(boardId) .orElseThrow(() -> new BoardNotFoundException()); Post post = new Post(); // 중략 return post; } } | cs |
스마트 UI와 비슷한 맥락으로 트랜잭션 스크립트는 스마트 서비스라고 부를 수 있다. 나아가 객체지향 보다는 절차지향에 가까운 사례이기에 절차지향의 문제점을 그대로 갖는다. 변경에 취약하고 확장에 취약하며 업무가 병렬로 처리되기 어렵다.
이러한 트랜잭션 스크립트 같은 코드는 서비스의 역할이 무엇인지, 아니면 객체지향을 스프링에 어떻게 적용해야 하는지 모르는 개발자들이 개발할 때 많이 만들어진다. 그래서 특히나 스프링을 배운 지 어마 안 된 개발자들이 코드를 작성하면 이런 유형의 코드가 만들어진다.
그래서 이 같은 패턴을 피하려면 서비스의 역할이 무엇인지 재고해야 한다. 서비스란 무엇이고 서비스의 역할이 어떤 것인지 이해해야 이 패턴을 피할 수 있다.
비즈니스 로직은 어디에 위치해야 할까?
비즈니스 로직은 도메인 모델에 위치해야 한다. 비즈니스 로직이 처리되는 주 영역은 서비스 컴포넌트가 아닌 도메인 모델이어야 하며 서비스는 도메인을 불러와서 도메인에 일을 시키는 정도의 역할만 해야 한다.
트랜잭션 스크립트 같은 코드가 발생하는 이유는 개발자가 '서비스는 비즈니스 로직을 처리하는 곳'이라고 생각하고 있기 때문이다. 애플리케이션의 본질은 도메인이며 서비스가 아니다. 서비스는 도메인을 위한 무대일 뿐이다. 그러니 서비스는 도메인이 협력할 무대만 제공하고 그 이상의 역할을 하지 않는 것이 좋다.
7. 서비스
서비스의 역할은 도메인 객체나 도메인 서비스라고 부리는 도메인에 일을 위임하는 공간이어야 한다. 그렇기 때문에 서비스 역할은 아래와 같이 크게 3가지 종류의 일을 해야 한다는 의미이다.
- 도메인 객체를 불러온다.
- 도메인 객체나 도메인 서비스에 일을 위임한다.
- 도메인 객체의 변경 사항을 저장한다.
7.1 Manager
컨트롤러는 '제어부'이고 리포지토리는 '저장소'이며 컴포넌트는 '구성 요소'이다. 이러한 컴포넌트는 모두 영문명을 한글로 번역하면 그 역할이 무엇인지 바로 알 수 있는 수준이라 이해하기가 크게 어렵지 않다. 그렇다면 서비스는 왜 서비스라고 부를까?
@Service 코드의 남겨진 주석을 확인해보면 @Service는 에릭 에반스의 DDD에서 영감을 받아 만들어진 애노테이션이고, 서비스는 J2EE 패턴 중 하나인 비즌니스 서비스 파사드처럼 사용될 수 있다고 남겨져있다.
DDD(Domain Driven Design)는 '도메인 주도 설계'라는 말 그대로 도메인을 중심에 놓고 소프트웨어를 설계하는 방법을 알려주는 개발 방법론이다. 이 방법론에서는 개발자가 복잡한 도메인을 이해하고 설계하는 방법을 알려준다. 그리고 도메인 전문가라고 부르는 사람과 소통하는 법, 도메인 문제를 해결할 설계 패턴, 도메인 모델링 방법 등을 알려준다.
도메인이라는 용어가 자주 등장하는데, 도메인을 다시 한 번 정의하고 가자. 도메인(domain)이란 비즈니스 영역이자 우리가 해결하고 싶은 문제 영역(domain)이다. 왜냐 우리가 소프트웨어를 개발하는 이유가 곧 도메인에서 발생하는 문제를 해결하기 위함이기 때문이다.
은행 시스템을 예로 들어보자. 도메인이란 비즈니스 영역이라 했으니 이 시스템의 도메인은 '은행'이다. 그러면 이제 이 은행 시스템에서 일하는 백엔드 개발자는 '신용', '예금' 같은 용어를 잘 이해하고 있어야 하며, 은행 업무가 어떻게 돌아가는지 알아야 한다. 즉 '은행'이라는 도메인에 대해 잘 알고 있어야 한다.
그렇기 때문에 DDD 세상에서는 '개발자는 개발만 잘하면 된다'라는 말이 통하지 않고, 도메인에 대해서도 잘 알고 있어야 한다. 하지만 현실적으로 개발도 잘하고 모든 도메인을 알고 있는 것은 불가하다. 따라서 DDD 세상의 개발자에게 요구되는 능력은 도메인 자체를 사전에 알고 있는 것이 아니라 도메인을 분석하고 탐색할 수 있는 능력이 요구된다.
그래서 개발자가 소프트웨어가 해결하려는 비즈니스 영역을 이해하는 과정을 보고 '도메인 탐색'이라 부른다. 도메인 탐색 과정은 '도메인 전문가'라고 불리는 집단과 소통하며 이뤄진다. 여기서 말하는 '도메인 전문가'는 해당 비즈니스 영역에 이미 종사 중이거나 이해도가 높은 사람을 말한다. DDD에서는 도메인 전문가와 개발자의 협력을 강조한다.
도메인을 탐색하고, 탐색한 내용을 바탕으로 소프트웨어를 설계한다. 이것이 DDD의 주요 핵심이다.
DDD의 창시자 에릭 에반스는 서비스를 이렇게 설명하였다.
자신의 본거지를 Entity나 Value Object에서 찾지 못하는 중요한 도메인 연산이 있다. 이들 중 일부는 본질적으로 사물이 아닌 활동이나 행동인데, 우리의 모델링 패러다임이 객체이므로 그러한 연산도 객체와 잘 어울리게끔 노력해야 한다.
이게 바로 스프링 서비스의 정체이다. 서비스는 도메인 객체가 처리하기 애매한 '연산' 자체를 표현하기 위한 컴포넌트이다.
예를 들어보자. 상품(Product), 쿠폰(Coupon), 사용자(User)의 마일리지(Mileage)라는 도메인이 있고, 물건의 가격을 계산하기 위해 다음과 같은 계산식을 사용한다.
가격 = 상품 가격 - (상품 가격 X 쿠폰 최대 할인율) - 사용자 마일리지
이 비즈니스 로직이 Product, Coupon, User 세 가지 도메인 모델 중 어디로 가도 어색하다. 다시 말해 가격을 계산하는 로직은 모든 도메인 객체가 처리하기 애매해다. 왜냐하면 이러한 로직을 능동적인 객체에 표현하는 것 자체가 어렵기 때문이다. 가격 계산 로직은 그 자체로 '연산'이며 행동이다. 그래서 객체로 표현되기 어렵고 '계산식'과 같은 형태로 표현되는 것이 오히려 더 자연스럽다.
이런 경우 PriceManager 라는 매니저 클래스를 만들고 비즈니스 로직을 이 클래스 안으로 옮기는 것이 합리적인 선택이다. 이렇게 만들어지는 '매니저(Manager)'가 바로 서비스이다. PriceManager, UserManager, PostManager 등등 클래스 이름의 접미어에 Manager가 나오면 접두어에 있는 모델을 관리하는 클래스를 뜻한다.
서비스 클래스는 곧 매니저 클래스다. 그리고 로직 자체가 '연산'이라서 어떠한 객체도 갖고 있기도 어려운 경우에 만들어지는 클래스가 서비스다.
스프링의 서비스 컴포넌트가 처리하는 일을 보면 다음과 같다.
- 저장소에서 데이터를 불러온다.
- 네트워크 호출 결과를 정리해서 객체에 넘겨준다.
- 저장소에 데이터를 저장하
이러한 로직 모두 '연산' 그 자체이므로 도메인 객체에 넣기 어렵지만 동시에 애플리케이션이 가치를 전달하기 위해서는 꼭 필요한 코드이므로 어딘가엔 반드시 존재해야 한다. 그래서 애플리케이션에 꼭 필요하지만 '연산' 그 자체로는 어떠한 객체도 갖고 있기 애매해서 만들어지는 별도의 클래스가 있다. 이것이 바로 서비스이고 매니저이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | @Service @RequiredArgsContructor public class ProductService { private final UserJpaRepository userJpaRepository; private final ProductJpaRepository productJpaRepository; private final CouponJpaRepository couponJpaRepository; public int calculatePrice(long userId, long productId) { User user = userJpaRepository.getById(userId); Product product = productJpaRepository.getById(productId); List<Coupon> coupons = couponJpaRepository.getByUserId(userId); PriceManager priceManager = new PriceManager(); return priceManager.calculate(user, product, coupons); } } | cs |
위 코드를 보면 서비스(ProductService)가 서비스(PriceManager)를 호출하고 있는 형태이다. 서비스가 서비스를 실행시키는 것은 좋은데, 이 둘을 구분할 필요가 있어보인다.
PriceManager는 도메인 시스템을 구축하기 위해 존재한다. 그리고 가격을 계산한다는 점과 가격을 계산하는 업무 규칙을 갖고 있으므로 '도메인'에 가까운 로직이다. 반면 ProductService는 스프링에서 사용하는 @Service 애노테이션을 사용하고 있고, 도메인에 필요한 비즈니스 업무 규칙을 갖고 있다기 보다는 애플리케이션이 돌아가는 데 필요한 연산을 갖고 있는 서비스이다. 그래서 도메인보다는 '애플리케이션의 실행'에 초점을 맞춰 개발된 서비스라고 볼 수 있다.
정리를 하자.
| 분류 | 역할 | 주요 행동 | 예시 |
| 도메인 | 비즈니스 로직을 처리 | 도메인 역할을 수행 다른 도메인과 협력 |
User, Product, Coupon |
| 도메인 서비스 | 비즈니스 '연산' 로직을 처리 | 도메인 협력을 중재 도메인 객체에 기술할 수 없는 연산 로직을 처리 |
PriceManager |
| 애플리케이션 서비스 | 애플리케이션 '연산 로직을 처리 | 도메인을 저장소에서 불러옴 도메인 서비스를 실행 도메인을 실행 |
ProductService |
절차지향을 동작하는 시스템을 객체지향을 만들려면 풍부한 도메인 객체를 만드는 작업을 먼저 해야 한다. 그렇게 만들고 난 뒤에 스프링의 서비스 컴포넌트는 도메인을 불러오고 도메인들이 협력하는 공간을 제공하기만 하도록 변경해야 한다.
이 말은 즉, 스프링의 서비스 컴포넌트는 저장소에서 객체를 불러오고, 객체에 일을 시키고, 객체를 반환하는 정도의 일만 처리하라는 의미이다. 그러면 이제 J2EE의 비즈니스 서비스 파사드 패턴처럼 사용할 수 있는 것이다. 즉 도메인과 도메인 서비스의 파사드(facade: 정문)처럼 사용할 수 있는 공간이 된다. 달리 말하면 스프링 서비스의 역할은 원래 딱 이정도여야 한다는 의미이기도 하다.