8. 레이어드 아키텍처
8.1 레이어드 아키텍처의 최소 조건
레이어드 아키텍처는 애플리케이션을 레이어로 나누고 각 레이어에 역할을 정한다. 대표적인 레이어로는 프레젠테이션, 비즈니스, 인프라스트럭처 같은 레이어가 있다. 한가지 유념해야 할 점은 레이어드 아키텍처는 한 사람에 의해 만들어진것이 아니라 여러 개발자의 필요에 의해 발전된 아키텍처이다. 그래서 사람마다 레이어드 아키텍처를 이해하는 깊이나 수준이 다르다. 누군가는 레이어를 단순히 파일을 구분하는 폴더 구조 정도로 이해하는 사람이 있고, 또 다른 누군가는 헥사고날 아키텍처 수준으로 사용한다.
레이어드 아키텍처에서 아키텍처란 "정책과 제약 조건을 이용해 목적을 달성"하는 것이다. 목적이 무엇인가에 따라 정책과 제약 조건은 변경될 수 있다는 것이다.
책에서 설명하는 레이어드 아키텍처를 만드는 최소 조건은 아래와 같다.
- 레이어 구조를 사용한다.
- 레이어간 의존 방향은 단방향으로 유지한다.
8.2 잘못된 레이어드 아키텍처
만약 당신에게 계정(Account) 시스템의 백엔드를 만들어 달라는 요청이 들어오면 어떤 작업부터 시작할 것인가? 크게 두 가지 유형으로 나뉘게 된다.
- JPA 엔티티 우선. JPA 엔티티를 어떻게 만들지 고민한다.
- API 엔드포인트 우선. 계정 시스템의 API 엔드포인트를 어떻게 만들지 고민한다.
이 두가지 유형 모두 문제가 있다. JPA 엔티티 우선 유형은 데이터 구현은 어떻게 할지, DDL은 어떤 식으로 작성해야 할지 우선적으로 고민하게 된다. 이는 데이터 위주의 사고, 절차지향적인 사고로 이어지게 되고 객체지향과는 거리가 멀어질 수 있다.
반대로 API 엔드포인트 우선 유형은 시스템을 인터페이스 관점에서 어떻게 사용해야 할지 먼저 떠올리게 된다. 그래서 컨트롤러를 먼저 생각한다. 핸들러를 어떻게 작성해야 할지 고민하고 어떤 매개변수가 필요한지 고민하고 구체적으로는 요청의 형태(RequestBody)나 응답(ResposeEntity)은 어때야 하는지 고민한다. 엔드포인트를 고민한다는 것은 시스템에 어떤 것이 필요할 지, 즉 도메인 요구사항 관점에서 보기 시작했다는 점에서 JPA 엔티티를 우선하는 접근 방식보다 조금 더 낫긴 하다. 하지만 API 엔드포인트를 고민한다는 것은 기술 스펙을 결정하는 일이다. 왜냐 도메인이 무엇인지 파악하기 전부터 이미 API 서버를 만들겠다는 목적을 드러내는 것과 같기 때문이다. 우리의 시스템은 API 서버 뿐만 아니라 웹소켓용 서버가 될 수 있고, 원격 호출을 위한 rRPC 서버가 될 수도 있고, 혹은 메시지 큐의 컨슈머가 될 수도 있다.
우리는 '스프링 API 서버 개발자'라고 불리고 싶은 것이 아니라 아니라 백엔드 서버 개발자가 되고 싶다. 이상적으로 기술 스펙은 도메인 요구사항을 문석하고 거기에 대응하는 해결 수단으로 선택돼야 하는 것이 맞다.
물론 대부분 어차피 스프링을 이용할 것이고 API 서버를 만들게 될 수도 있지만 이런 생각의 차이가 시스템과 개발자의 한계를 결정한다.
정리하면, JPA를 먼저 고민하게 된다면 프로그램이 JPA에 지나치게 의존하게 되고, 컨트롤러를 먼저 고민하게 된다면 프로그램이 스프링에 지나치게 의존하게 된다. '지나치게 의존한다'는 말은 애플리케이션이 그것 없이는 설명할 수 없는 상태라는 말이다. 진정한 의미의 백엔드 개발자는 스프링이나 JPA 없이도 성립할 수 있는 애플리케이션을 만들 수 있어야 한다!
애플리케이션의 본질은 도메인이지 스프링이나 JPA가 아니다. 애플리케이션을 개발한다는 것은 도메인을 파악하고, 이에 다른 도메인 모델을 구성하고, 도메인 모델을 표현하는 데 적합한 언어를 선택하고, 도메인 모델을 만들고, 도메인 기능을 제공할 기술을 선택한다는 것이다.
8.3 진화하는 아키텍처
JPA 부터 시작하는 상향식 접근법도 부자연스럽고, 컨트롤러 부터 시작하는 하향식 접근법도 부자연스럽다면 어떻게 해야 할까? 바로 시스템 개발의 첫 시작을 도메인으로 두면 된다.
프레젠테이션 레이어, 비즈니스 레이어, 인프라스트럭처 레이어가 있을 때 도메인을 개발하려면 비즈니스 레이어부터 개발하면 된다. 아니 다시말해 비즈니스 레이어 중에서도 도메인을 가장 먼저 개발해야 한다.

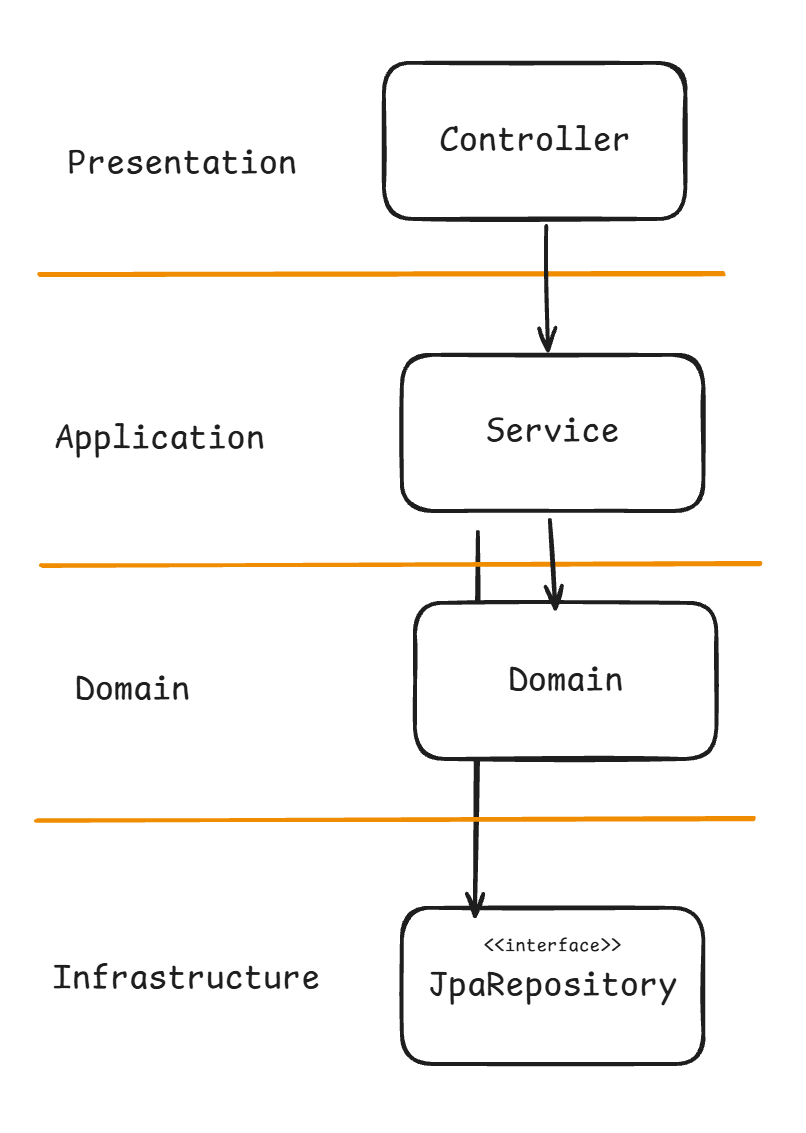
레이어드 아키텍처에서 인지 모델을 위의 왼쪽 그럼처럼 총 3가지의 레이어만 있던 형태에서 도메인 레이어를 추가하였고, 비즈니스 레이어를 애플리케이션 레이어와 도메인 레이어로 분리시켰다.
도메인 레이어는 객체지향적인 도메인 모델들이 활동하는 공간이다. 그리고 도메인 레이어의 또 한가지 특징은 이 레이어에 있는 객체들을 작성할 때는 순수 자바 코드로 작성해야 한다는 것이다. 이는 도메인 레이어를 외부 라이브러리에 의존하지 않고 자유롭게 만들기 위함이다.
하지만 현재 총 네가지의 레이어로 구분한 형태에도 문제점이 있다. 바로 애플리케이션 레이어가 JPA에 강하게 의존한다는 점이다. 만약 JPA 대신 다른 라이브러리를 써야 하는 상황이 온다면 인프라스트럭쳐 레이어 뿐만 아니라 애플리케이션 레이어에도 굉장히 많은 변화가 일어날 것이다. 즉 현재의 구조에서 인프라스트럭처 레이어가 변경된다면 애플리케이션을 유지보수하는 것이 어려워진다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | @Service @RequiredArgsConstructor public class AccountService { // 더이상 Jpa를 사용하지 않으니 영향 받음 private final AccountJpaRepository accountJpaRepository; @Transactional public Account updateNicknameById(long id, String nickname) { // Jpa의 @Entity로 개발된 AccountJpaEntity의 toModel 메서드를 실행하므로 영향 받음 Account account = accountJpaRepository.findById(id) .orElseThrow(() -> new NotFoundException("account = ", id)) .toModel(); account = account.withNickname(nickname); // Jpa의 Repository를 사용하고 있고 @Entity를 사용하고 있으니 영향 받음 return accountJpaRepository.save(AccountJpaEntity.from(account)) .toModel(); } } | cs |
평소에 우리가 작성하던 서비스 코드인데 JPA 대신 다른 라이브러리로 변경된다면 거의 모든 부분에서 영향을 받는다. 그래서 우리는 애플리케이션 레이어에 위치한 AccountService 컴포넌트가 인프라스트럭처 레이어에 위치한 JPA에 의존하는 상황을 제거하고 싶다. 의존성 역전을 사용해 이 문제를 해결할 수 있다. (그런데 정말 과연 해결해야 할 문제일까도 고민해보는 게 좋을 것 같다.)

코드는 아래와 같은 형태가 될 것이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | @Service @RequiredArgsConstructor public class AccountService { private final AccountRepository accountRepository; @Transactional public Account updateNicknameById(long id, String nickname) { Account account = accountRepository.findById(id); account = account.withNickname(nickname); accountRepository.save(account); } } public interface AccountRepository { Account findById(long id); void save(Account account); } @Repository @RequiredArgsConstructor public class AccountRepositoryImpl implements AccountRepository { private final AccountJpaRepository accountJpaRepository; @Override public Account findById(long id) { return accountJpaRepository.findById(id) .orElseThrow(() -> new NotFoundException("account = ", id)) .toModel(); } @Override @Transactional public void save(Account account) { accountJpaRepository.save(AccountJpaEntity.from(account)); } } | cs |
굉장히 재미있는 구조가 되었다. AccountService는 Jpa에 의존하지 않고 있지도 인프라스트럭처 레이어에 의존하고 있지도 않고, AccountRepository는 Jpa에 의존하고 있지 않다.
이제 이 프로젝트는 데이터베이스의 형태에 영향을 받지 않게 되었다. 다시 말해 꼭 RDB일 필요가 없이 MongoDB를 사용해도 되고, 다른 NoSQL을 사용해도 된다.
이는 레이어 간 연결에 의존성 역전을 적용함으로써 유연한 설계를 얻게 된 결과이다.
다시 정리하면 애플리케이션 레이어와 인프라스트럭처 레이어에 의존성 역전을 적용함으로써 애플리케이션이 더 이상 JPA와 강결합되지 않게 변경하였다. 더불어 데이터베이스의 형태에도 영향을 받지 않는 애플리케이션 설계를 얻을 수 있었다. 이 원리를 똑같이 프레젠테이션 레이어에도 적용시킬 수 있다.

코드는 아래와 같이 구현될 것이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | @RestController @RequiredArgsConstructor @RequestMappint("/account") public class AccountController { private final AccountService accountService; @PatchMappint("{id}") public ResponseEntity<Account> patchProperties( @PathVariable long id, @RequestBody @Valid PatchAccountRequest request ) { Account updated = accountService.updateNicknameById(id, nickname); return ResponseEntity.ok(updated); } } @Service @RequiredArgsConstructor public class AccountServiceImpl implements AccountService { private final AccountRepository accountRepository; @Override @Transactional public Account updateNicknameById(long id, String nickname) { Account account = accountRepository.findById(id); account = account.withNickname(nickname); accountRepository.save(account); } } public interface AccountService { Account updateNicknameById(long id, String nickname); } | cs |
이렇게 프레젠테이션 영역까지 의존성 역전을 적용했을 때 긍정적인 해석과 부정적인 해석이 나올 수 있다.
긍정적인 해석으로는 의존성 역전을 적용해 더 유연한 구조를 갖게 되었다는 의견이다. 그리고 애플리케이션과 스프링 웹 프레임워크의 결합도 끊을 수 있게 됐다고 볼 수 있다.
부정적인 해석으로는 굳이 프레젠테이션 레이어에 의존성 역전을 적용할 필요가 있냐는 의견이다. 의존성 역전을 적용한다고 해도 얻을 수 있는 이점이 모호하다는 것이다. 예를 들어 웹 애플리케이션으로 만들어진 프로젝트가 요구사항이 변경되어 시스템이 웹 애플리케이션이 아니라 메시지 시스템의 컨슈머 역할을 하는 애플리케이션으로 개발돼야 한다면, 프레젠테이션 영역만 변경하면 된다. 하지만 이는 프레젠테이션 레이어에 의존성 역전을 적용하든 적용하지 않든 같다. 상식적으로 프레젠테이션 레이어는 그대로인데 애플리케이션 레이어가 변경되는 일이 일어나긴 어렵다. 왜냐 애플리케이션의 본질인 애플리케이션, 도메인 레이어가 다른 형태로 변경될 일은 없기 때문이다.
양측 의견이 모두 정당하기에 어느 쪽이 맞거나 틀리다고 할 수 없다. 애초에 아키텍처의 세계에는 정답이란 것이 존재하지 않는다. 오롯이 문제 상황과 문제 상황에 부딪혔을 때 해결해 가는 과정만이 존재할 뿐이다.
그렇기에 원리를 이해하고 해결 방법을 아는 것이 중요하다. 문제 상황에 부딪혔을 때 문제를 해결할 수 있는 방법과 그 이유를 최대한 많이 알아둬야 하는 것이다. 결국 소프트웨어를 개발하면서 벌어지는 모든 의사결정은 트레이드오프 싸움이다. 그러므로 정해진 무언가를 무작정 따르기보다 문제 상황에 놓였을 때 선택할 수 있는 가능성을 나열하고 장단을 비교해 적용 여부를 판단하는 사람이 되어보자.
8.4 새로운 접근법
앞서 말했던 계정 시스템을 만들어야 한다면 어디서부터 개발을 시작해야 할지에 대한 답변으로 도메인 레이어부터 개발하면 된다고 답을 내렸다. 그러면 이는 상향식 접근법인가 하향식 접근법인가 둘 다 애매하다. 왜냐 시작이 중간부터이기 때문이다.

근데 과연 그럴까?
도메인 부터 개발한다는 것은 명명백백히 상향식 접근 방법이다. 도메인 모델을 잡고 아래로 쭈욱 당겨보면 아래와 같은 형태가 된다.
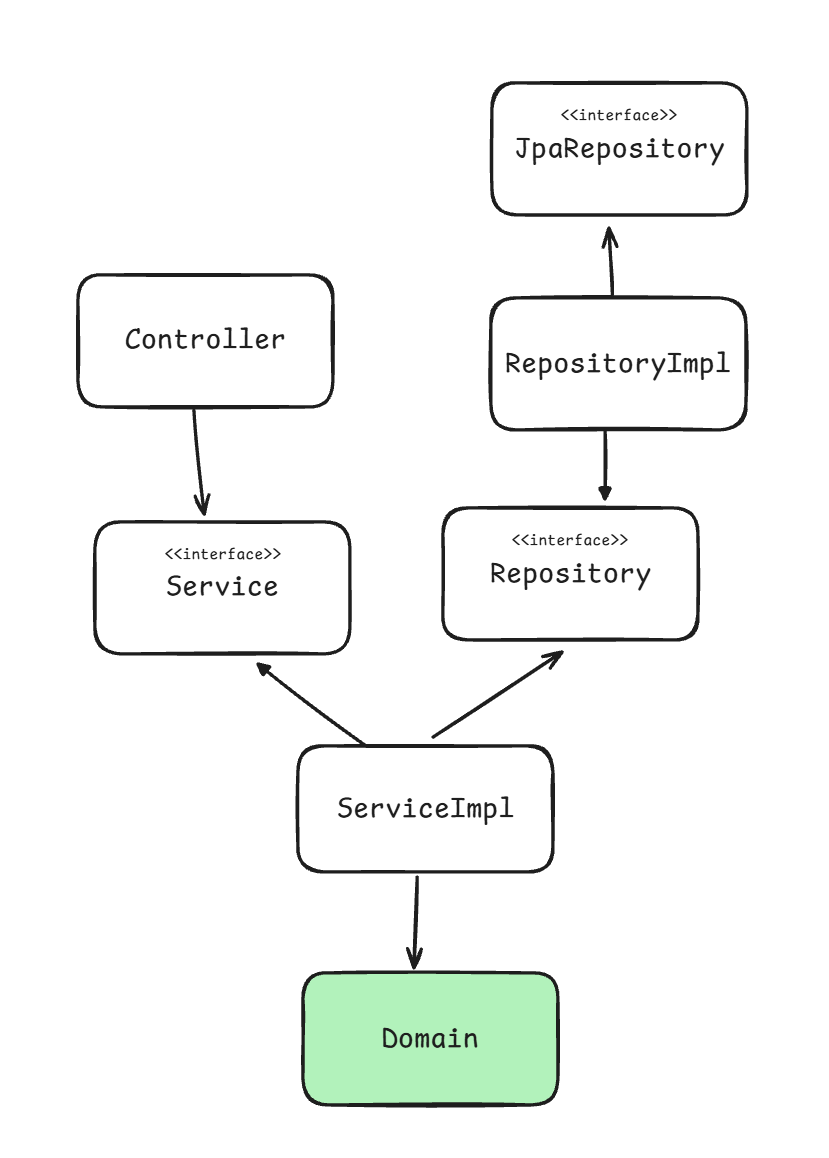
위는 사실 헥사고날 아키텍처와도 동일한 형태이다. (헥사고날이 무엇인지는 나중에 시간이 난다면 더 공부해보기로...)
이처럼 아키텍처를 암기하는 게 아니라 이해하고 나면 좀 더 넓은 시야를 갖게 될 수 있다. 불필요한 레이어 경게도 지우고 컴포넌트의 위치를 바꿔가며 이야기를 계속 변주할 수 있게 된다. 따라서 아키텍처를 보면서 아키텍처가 어떻게 생겼는지 외우는 것보다 아키텍처를 해석할 수 있는 것이 우선이다.
아키텍처의 핵심은 생김새가 아니다. 어디까지가 어떤 레이어인지, 이게 육각형 모양인지, 팔각형 모양인지가 중요한 것이 아니다. '왜 이런 형태를 띠고 있는지'가 중요하다.